建立环境#
安装 pandas#
sudo apt-get install build-essential python-dev
sudo apt-get install python-pandas python-tk
sudo apt-get install python-scipy python-matplotlib python-tables
sudo apt-get install python-numexpr python-xlrd python-statsmodels
sudo apt-get install python-openpyxl python-xlwt python-bs4
安装 ipython-notebook#
sudo pip install "ipython[notebook]"
sudo pip install pygments
运行 ipython-notebook#
ipython notebook
#如果你使用matplotlib内嵌进网页中,那么需要运行:
ipython notebook --matplotlib inline
导入 pandas#
import pandas as pd
import numpy as np
读入数据#
# 读入 CSV 格式数据
# 数据来源:http://boxofficemojo.com/daily/
df_movies = pd.read_csv('movies.csv', sep='\t', encoding='utf-8')
df_movies.head()
df_movies = pd.read_csv('movies.csv', sep='\t', encoding='utf-8',thousands=',',escapechar='$')
df_movies.head()
复制数据#
df = df_movies.copy()
df.head(3)
导出数据#
#导出周六的数据,格式为 CSV
df[ (df['Day'] == 'Sat') ].to_csv('test_output.csv', mode='w', encoding='utf-8', index=False)
#在前面的文件中追加周日的数据
df[ (df['Day'] == 'Sun') ].to_csv('test_output.csv', mode='a', header=False, encoding='utf-8', index=False)
显示数据#
#显示开头的数据,缺省显示 5 条
df.head()
#显示开头的数据,指定显示 3 条
df.head(3)
#显示末尾的数据,缺省显示 5 条
df.tail()
#显示末尾的数据,缺省显示 2 条
df.tail(2)
#只显示指定的行和列
df.iloc[[1,3,5],[0,1,2,3]]
df.loc[[1,3,5],['Date', 'Gross']]
操作单元#
df = df_movies.copy()
# 单元格赋值
# 单个单元格赋值
df.ix[0, u'#1 Movie'] = u'土豆之歌'
df.loc[df.index[1], u'Gross']= 999
df.head(3)
# 多单个单元格赋值
df.loc[df.index[0:2], u'Gross'] = [100, 200]
df.head(3)
操作列#
改变列头#
使用 columns 属性#
df = df_movies.copy()
#用一个列表来显式地指定,列表长度必须与列数一致
# 示例 1
df.columns = [u'row', u'date', u'weekday', u'day', u'top10gross', u'no1moive', u'gross']
df.head()
# 示例 2 :大写转小写
df.columns = [c.lower() for c in df.columns]
df.head()
使用 rename 方法#
# 示例 1 :小写转大写
df = df.rename(columns=lambda x: x.upper())
df.tail(3)
# 示例 2 :改变特定的列头
df = df.rename(columns={'DATE': u'日期', 'GROSS': u'票房'})
df.head()
打印列类型#
df.columns.to_series().groupby(df.dtypes).groups
# 打印列类型(清晰打印中文)
types = df.columns.to_series().groupby(df.dtypes).groups
for key, value in types.items():
print key,':\t', ','.join(value)
插入列#
df = df_movies.copy()
# 方式一:在末尾添加
df['memo'] = pd.Series('', index=df.index)
df.head(3)
# 方式二:在中间插入
df = df_movies.copy()
df.insert(loc=1, column=u'year', value=u'2015')
df.head(3)
# 根据现有值生成一个新的列
df = df_movies.copy()
df.insert(loc = 5 , column=u'OtherGross', value=df[u'Top 10 Gross'] - df[u'Gross'])
df.head(3)
# 根据现有值生成多个新的列
# 方法一
df = df_movies.copy()
def process_date_col(text):
#根据日期生成月份和日两个新的列
if pd.isnull(text):
month = day = np.nan
else:
month, day = text.split('.')
return pd.Series([month, day])
df[[u'month', u'day']] = df.Date.apply(process_date_col)
df.head()
# 方法二(结果同上,但是没有方法一好)
df = df_movies.copy()
for idx, row in df.iterrows():
df.ix[idx, u'month'], df.ix[idx, 'day'] = process_date_col(row[u'Date'])
df.head()
改变列值#
df = df_movies.copy()
#根据一列的值改变另一列
df[u'#1 Movie'] = df[u'#1 Movie'].apply(lambda x: x[::-1])
df.head(3)
# 同时改变多个列的值
cols = [u'Gross', u'Top 10 Gross']
df[cols] = df[cols].applymap(lambda x: x/10000)
df.head(3)
操作行#
df = df_movies.copy()
# 添加一个空行
df = df.append(pd.Series(
[np.nan]*len(df.columns), # Fill cells with NaNs
index=df.columns),
ignore_index=True)
df.tail(3)
空值处理(NaN)#
# 计数有空值的行
nans = df.shape[0] - df.dropna().shape[0]
print(u'一共有 %d 行出现空值' % nans)
# 填充空值为`无`
df.fillna(value=u'无', inplace=True)
df.tail()
df = df_movies.copy()
# 添加一个空行
df = df.append(pd.Series(
[np.nan]*len(df.columns), # Fill cells with NaNs
index=df.columns),
ignore_index=True)
# 根据某一列排序(由低到高)
df.sort(u'Gross', ascending=True, inplace=True)
df.head()
# 排序后重新编制索引
df.index = range(1,len(df.index)+1)
df.head()
df = df_movies.copy()
# 根据列类型过滤
# 只选择字符串型的列
df.loc[:, (df.dtypes == np.dtype('O')).values].head()
# 选择 artifact 为空值的行
df.ix[0, u'Gross'] = np.nan
df.ix[3, u'Gross'] = np.nan
df[df[u'Gross'].isnull()].head()
# 选择'Gross'为非空值的行
df[df[u'Gross'].notnull()].head()
# 根据条件过滤
df[ (df[u'Day'] == u'Sat') | (df[u'Day#'] <= 32) ]
df[ (df[u'Day'] == u'Sat') & (df[u'Day#'] <= 32) ]
统计:计数,平均,最大,最小,方差,标准差#
同比,环比#
图形化#
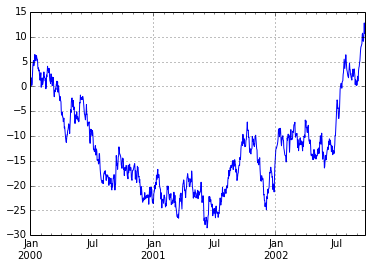
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
ts = ts.cumsum()
ts.plot()
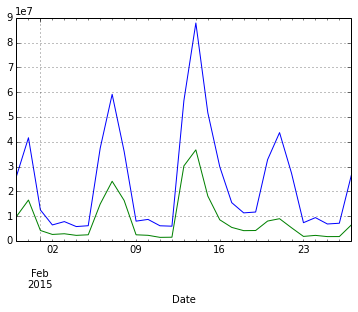
df = df_movies.copy()
df[u'Date'] = pd.to_datetime(df[u'Date'] + ',2015' )
df.head()
df.plot(x='Date', y=['Top 10 Gross', 'Gross'])
使用另一个 DataFrame 来更新数据#
df_1 = df_movies.copy()
df_2 = pd.DataFrame({u'#1 Movie':[u'American Sniper',
u'SpongeBob',
u'Fifty Shades of Grey'],
u'chs':[u'美国阻击手',
u'海绵宝宝',
u'五十度灰']})
df_1.head()
df_2.head()
pd.merge(df_1, df_2, on=u'#1 Movie').head()